前言
在1月中旬了解到了这个项目SDT,可以训练/生成自己的字体,感觉使用不错。仅仅需要投喂少量字体就可以根据字体的特点训练/生成一套你的专属字体!
虽说能够生成,但是与实际的还是有所出入,本篇文章使用了已训练好的模型进行使用。该项目还是不够成熟,还是得再接再厉
开始
python 3.8
pytorch(使用GPU请根据下文内容下载) >=1.8
easydict 1.9
einops 0.4.1
SDT的配置
训练/生成模型
将SDT clone到本地之后可以自己训练模型或者下载已训练好的模型
反正我是下载已经训练好的模型到本地,感觉重新训练没什么必要
自己根据图片路径来理解文件位置吧
https://pan.baidu.com/s/1RNQSRhBAEFPe2kFXsHZfLA?pwd=xu9u
导入字体

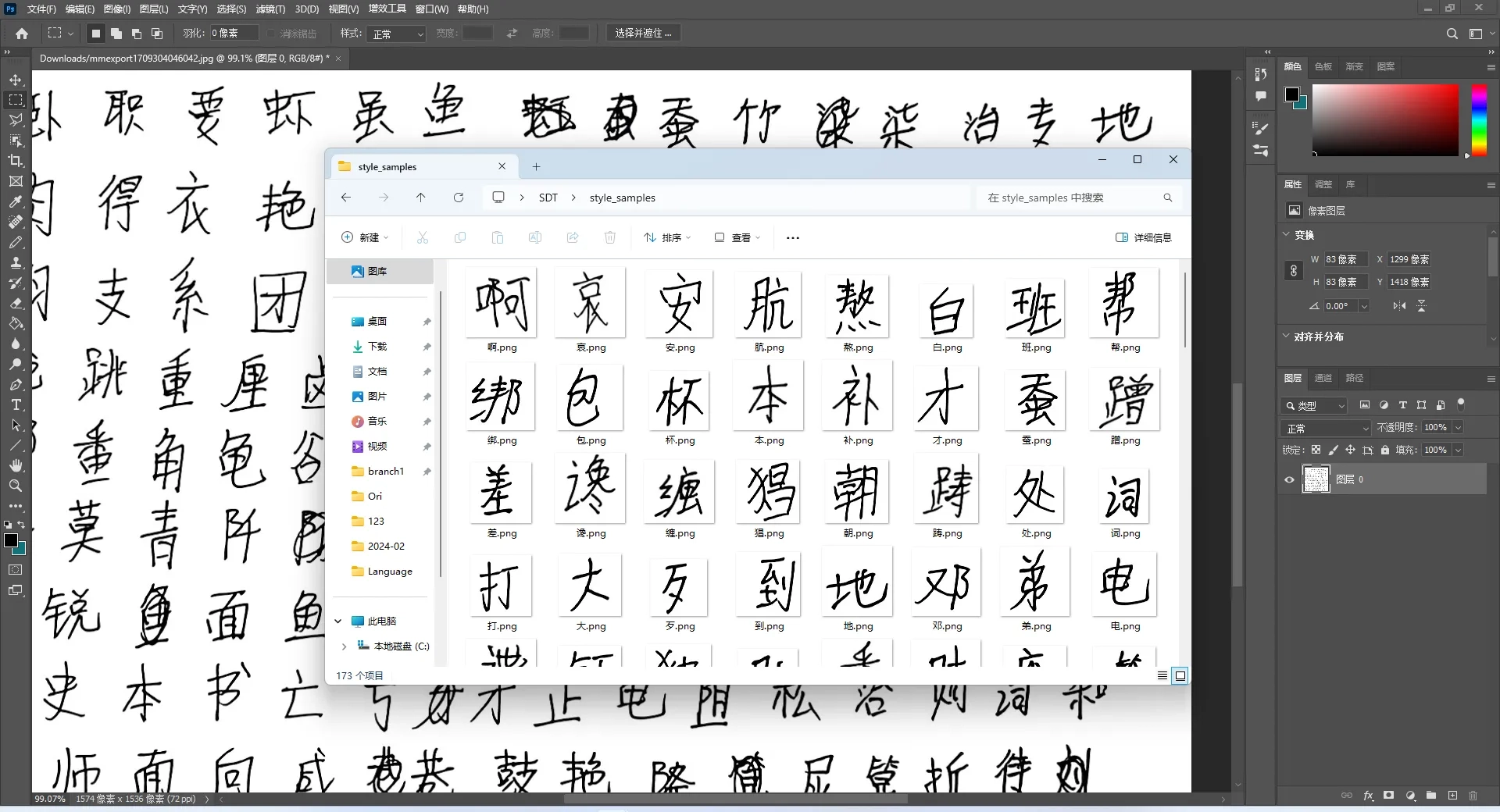
可以使用SAI2的二值化模式进行书写!
裁剪为差不多是正方形的图片就行,SDT会自动设置为64*64
图片放到style_samples内即可,像图片里面那样
GPU配置
pytorch的安装
前置环境
你需要根据你电脑的Driver版本来下载对于的CUDA版本
在CMD中输入nvidia-smi即可查看
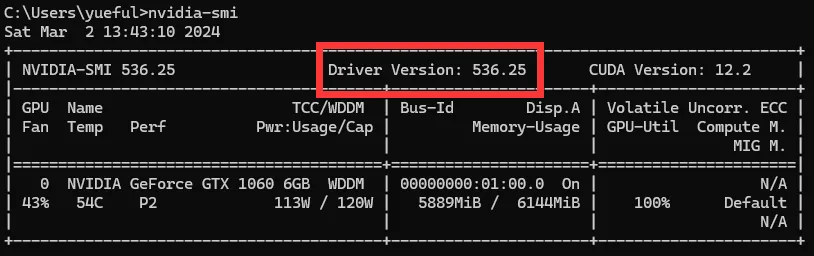
通过如下网站查询对应的CUDA版本
https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html
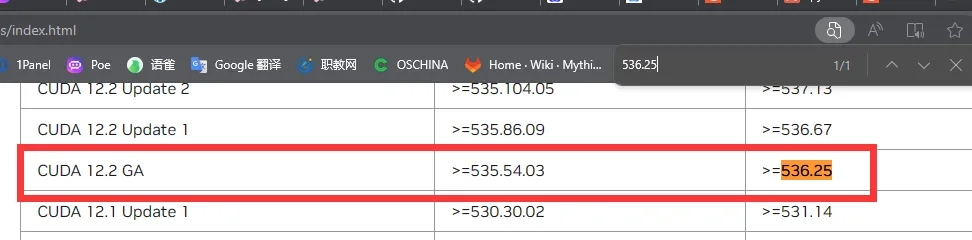
再通过如下网站进入对应的CUDA下载
https://developer.nvidia.com/cuda-toolkit-archive

下载方式自选,我建议是local,毕竟network下载方式在国内不稳定

安装途中可以下载cuDNN
前往https://developer.nvidia.com/rdp/cudnn-archive查找对应CUDA版本的cuDNN
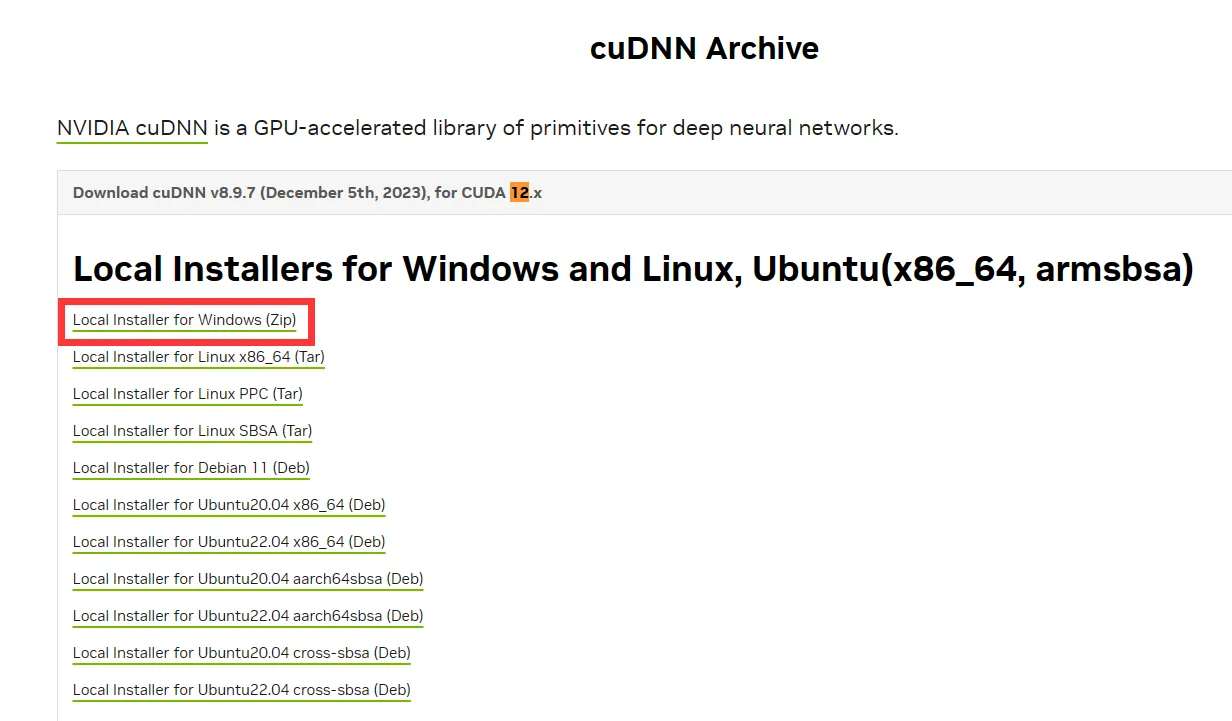
下载完成后将.zip内的内容给复制到安装CUDA的目录内
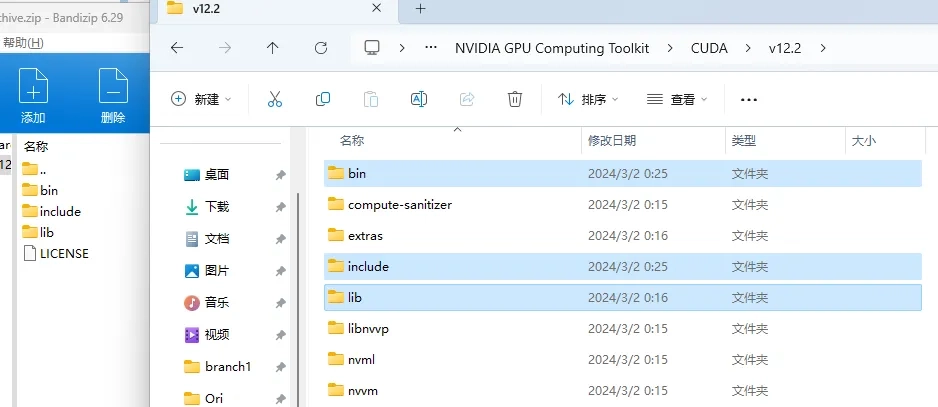
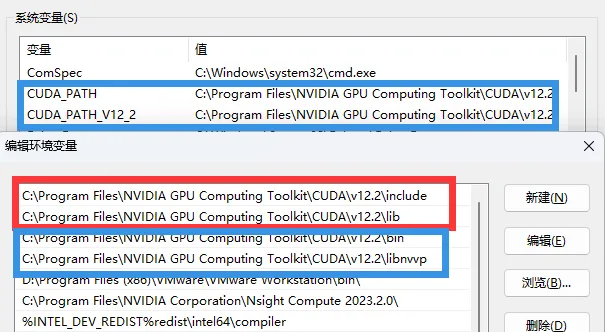
然后配置环境变量,安装CUDA时应该会自动配置变量,不用管
在Path中配置cuDNN的环境变量
红框是cuDNN的环境变量,蓝框是CUDA的环境变量(不用管)
安装pytorch
现在可以前往https://pytorch.org/get-started/locally/生成对应的pytorch命令下载pytorch了
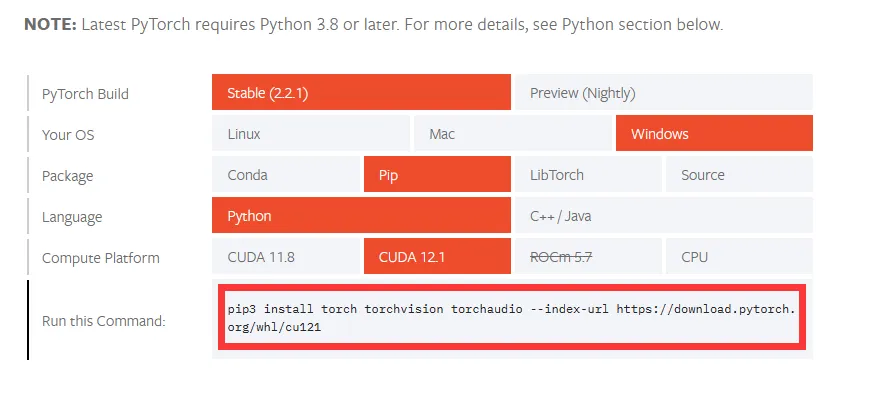
这样GPU运行的配置环境就完成了
开始训练/生成
现在,你已经完成了上面的GPU的配置,可以开始训练/生成了!
在根目录输入如下命令即可开始训练/生成模型
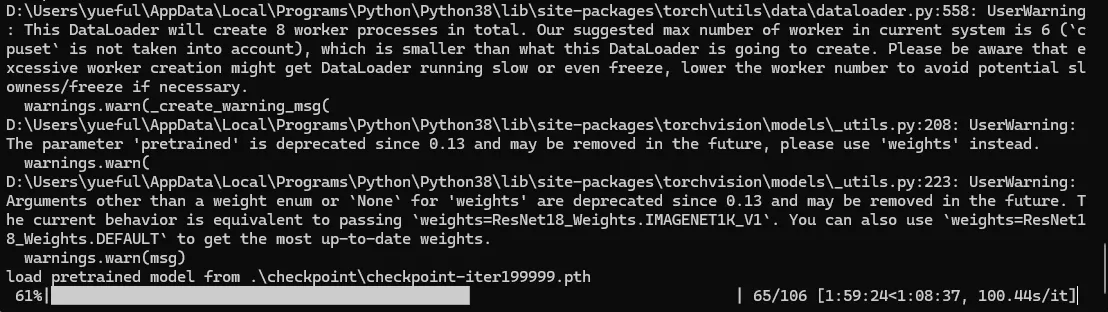
python user_generate.py --pretrained_model .\checkpoint\checkpoint-iter199999.pth --style_path .\style_samples
现如下内容则说明开始训练/生成了,耐心等待即可
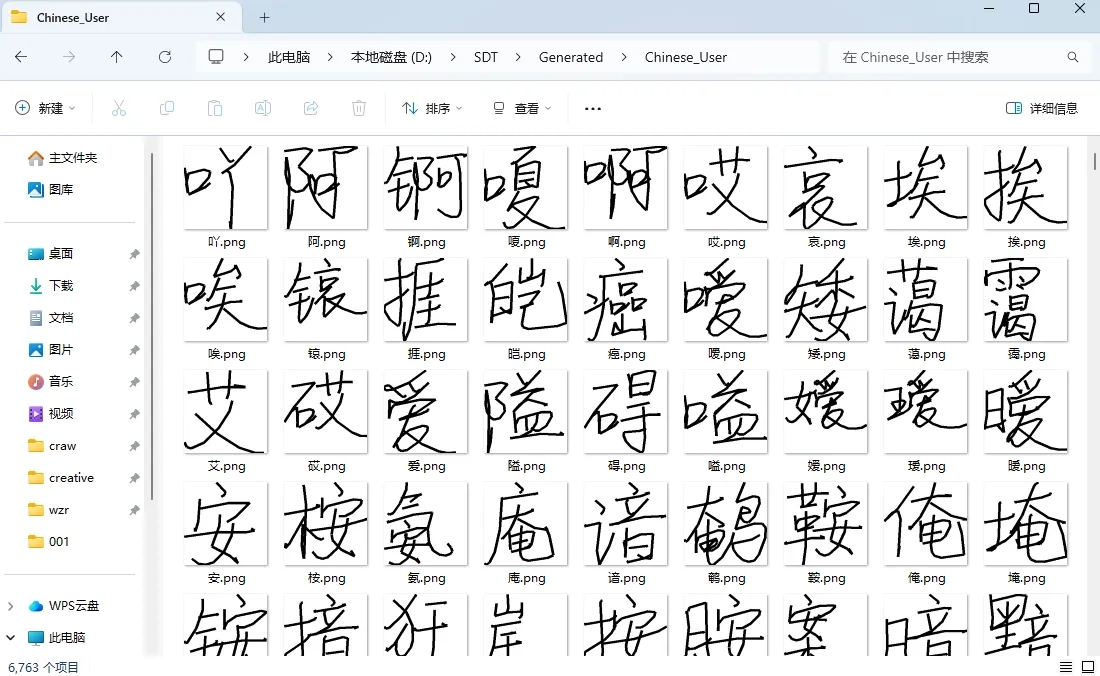
训练/生成完成应该是有6763个文件的,像我这样就是训练/生成好了的
生成字体文件
生成网站 制作个人字体ttf (jumengfang.com)
使用方法 格式转换之svg转ttf、dxf转ttf、图片转ttf、ttf转svg/png_哔哩哔哩_bilibili
我是直接导入png图片进行生成ttf的,转换过程是在电脑本地运行的,不是上传到服务器,所以你的cpu性能决定是转换速度
效果展示
两个是训练/生成出来的,两个是我自己实际写出来的,可以进行参考看看。红框就是训练出来的字体

第一个是用纸写然后ORC识别然后生成出来然后生成的
第二个是用数位板写出来的
第三个是平时那种语文作文的字体手写的
第四个是抄书时的字体
使用数位板生成写的我就是慢慢写的,相似度还是挺高的,但是还是不足,就喂了50个字体。
对照以后纸写然后ORC识别就算二值化了还是有噪点,很容易这样狂草
常见问题
遇到如下问题是缺少了six,请用pip下载即可,反正内容相同的都是缺库
像是opencv这种库你直接pip install cv2是找不到的,是opencv-python
如果下载失败可以百度'pip下载opencv'这样看库的名字
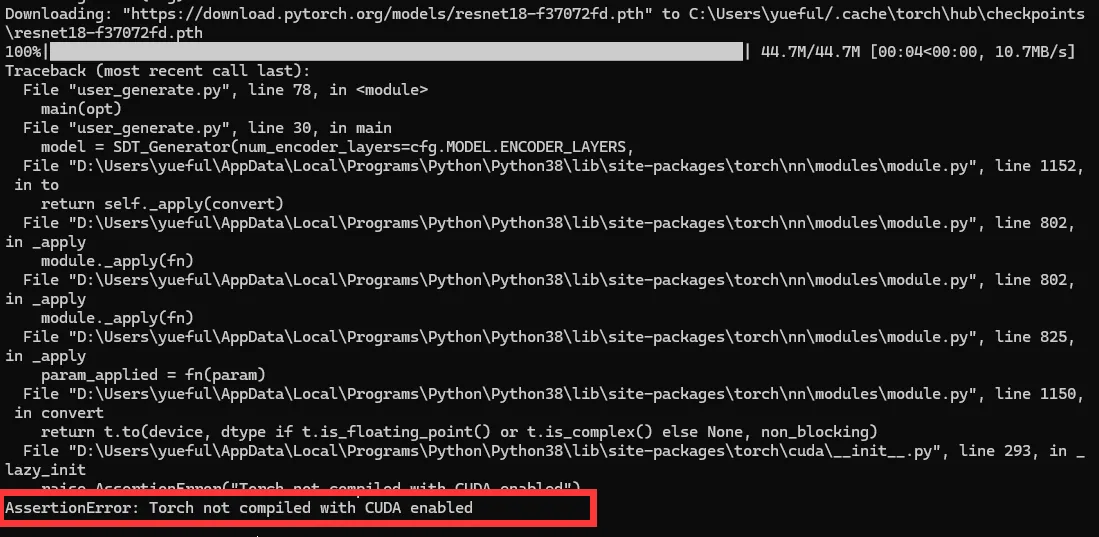
遇到如下问题是没有正确安装CUDA或cuDNN,请确定是否下载错误CUDA或cuDNN或pytorch的版本
遇到狂草字体可以尝试将图片二值化处理
然后再进行训练/生成
可以运行以下Python脚本
//ChatGPT
from PIL import Image
import os
# 指定源文件夹路径
source_folder = r'C:\Users\yueful\Desktop\a'
# 指定目标文件夹路径
target_folder = r'D:\SDT\style_samples'
# 获取源文件夹中的所有文件
file_list = os.listdir(source_folder)
# 遍历源文件夹中的每个文件
for file_name in file_list:
# 构建源文件的完整路径
source_file = os.path.join(source_folder, file_name)
# 构建目标文件的完整路径
target_file = os.path.join(target_folder, file_name)
# 打开图片
image = Image.open(source_file)
# 将图片转换为灰度图
gray_image = image.convert('L')
# 进行二值化处理
threshold = 128 # 阈值,用于控制二值化的结果
binary_image = gray_image.point(lambda x: 0 if x < threshold else 255, '1')
# 保存二值化后的图片
binary_image.save(target_file)
# 关闭图片
image.close()
gray_image.close()
binary_image.close()
print("图片二值化完成")参考文献/资料
环境配置:安装GPU版本Pytorch(全网最详细过程)_安装gpu版本的pytorch-CSDN博客
使用方法:教程:如何生成自己的个性化手写文字? · Issue #43 · dailenson/SDT (github.com)
二值化优化狂草:有没有可以自行解决输出字体狂草风格的方法 · Issue #59 · dailenson/SDT (github.com)
了解项目:我自己都看不懂的手写字,是怎么被计算机看懂的?【差评君】_哔哩哔哩_bilibili
使用数位板写字体:教程:从手写字体到A4纸打印(GPU篇) · Issue #78 · dailenson/SDT (github.com)
Comments 4 条评论
来过!
这是我找到唯一一个的sdt博客,不过我其实二值化了,他还是很丑。
@alalal 哈哈,用手写板吧。拍照扫出来然后二值化还是很狂草
@alalal 哈哈,用手写板不会出现这种问题